
The Golem —
An Artificial Intelligence Typography Experiment.
2021
![]()
![]()
![]()
![]()




The Golem is one of the earliest artificial intelligence (AI) prototypes. Originally a Jewish myth about an anthropoid figure of clay that was brought to life by virtue of kabbalistic theurgy. The Golem in this story is mute, a most significant aspect, that marks its inferior status to that of a human. Although human-like, the Golem cannot speak and hence lacks the divine connection humans have with god through their shared power of language. It is ironic, yet telling, that although the techniques that create the Golem are substantially linguistic, the result is considered to be (in most accounts) a speechless being.
![]()

Can AI give the Golem agency in the form of a Hebrew typeface it can communicate in?
Could a machine learning model be trained to generate realistic legible typefaces, in a language it cannot understand?
These questions set off the research into generative image tools, with the hypothesis that the machine would be able to generate images of typefaces that contained recognizable, yet new letterforms. These new generated typefaces would be visually based on all the typefaces given to the algorithm.
By using machine learning, instead of having the designer producing the content (the letterforms of the typeface), the designer is only responsible for the data input and duration of the experiment (how many training steps the model would have). The algorithm is then able to assess the dataset, take an action on it, compare the data against itself, determine likeness, and repeat the process if necessary. Once the desired level of similarity is achieved, the data can then be processed into an output - the generated typeface.
Could a machine learning model be trained to generate realistic legible typefaces, in a language it cannot understand?
These questions set off the research into generative image tools, with the hypothesis that the machine would be able to generate images of typefaces that contained recognizable, yet new letterforms. These new generated typefaces would be visually based on all the typefaces given to the algorithm.
By using machine learning, instead of having the designer producing the content (the letterforms of the typeface), the designer is only responsible for the data input and duration of the experiment (how many training steps the model would have). The algorithm is then able to assess the dataset, take an action on it, compare the data against itself, determine likeness, and repeat the process if necessary. Once the desired level of similarity is achieved, the data can then be processed into an output - the generated typeface.
— The Approach
First step in setting up the machine learning model was to create the dataset. This dataset was constructed of 150 glyphs per typeface (hebrew letters, latin upper and lowercase letters, numerals, punctuation, currency and math signs) of all available hebrew typefaces on Google Fonts, Adobe Fonts and other free fonts, organised as individual image-per-glyph dataset.
A styleGAN2 model was picked to be trained in RunwayML on this dataset.
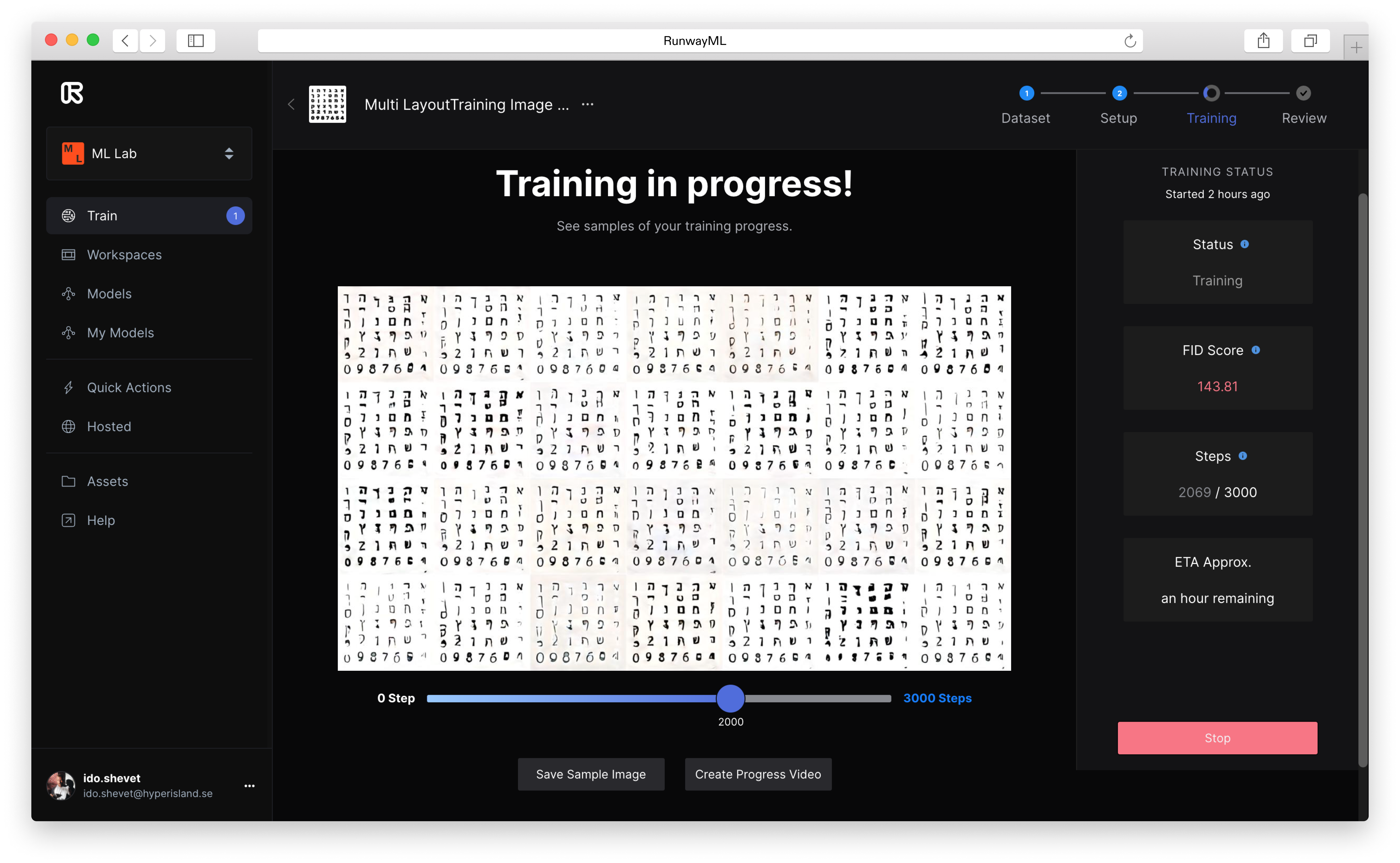
But first, what are GANs?
Generative Adversarial Networks (GANs) are one of the most interesting ideas in computer science today (the one you probably know from generating realistic looking human faces). Two models are trained simultaneously by an adversarial process. A generator learns to create images that look real, while a discriminator learns to tell real images apart from fakes.
During training, the generator progressively becomes better at creating images that look real, while the discriminator becomes better at telling them apart. The process reaches equilibrium when the discriminator can no longer distinguish real images from fakes.

The machine learning algorithm was trained using this dataset of images as reference so that it could then begin to recognize similarities between each glyph. A larger amount of training steps will result in an output that more closely resembles the original data.

These expermentations generated output showing a new typeface per frame—and an oscillation between different styles and kinds of typefaces, if you put one output frame after the other as a sequence.

10,000 Training steps / ~8 hrs cpu
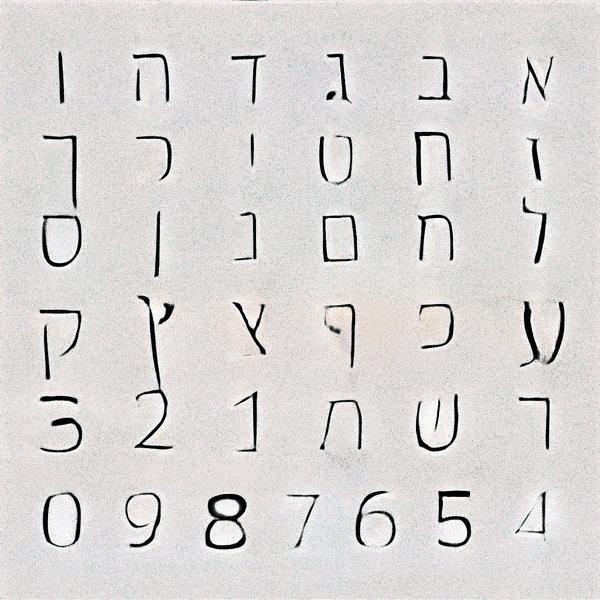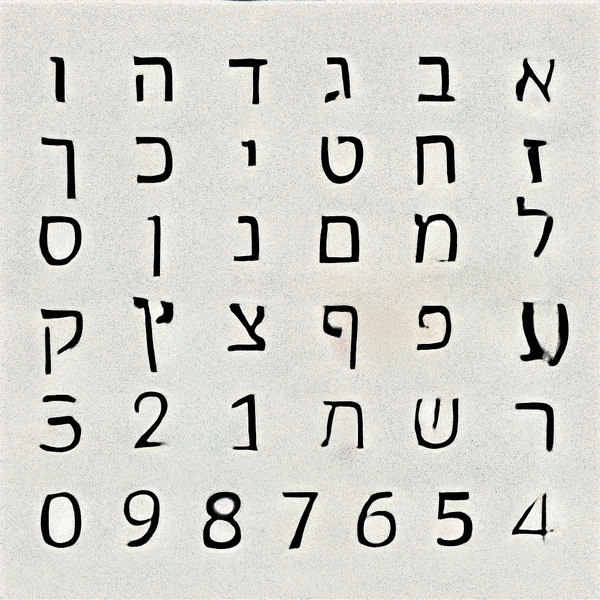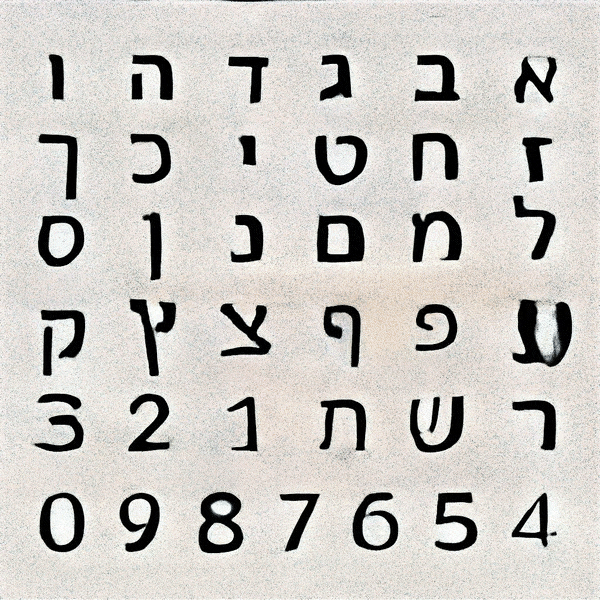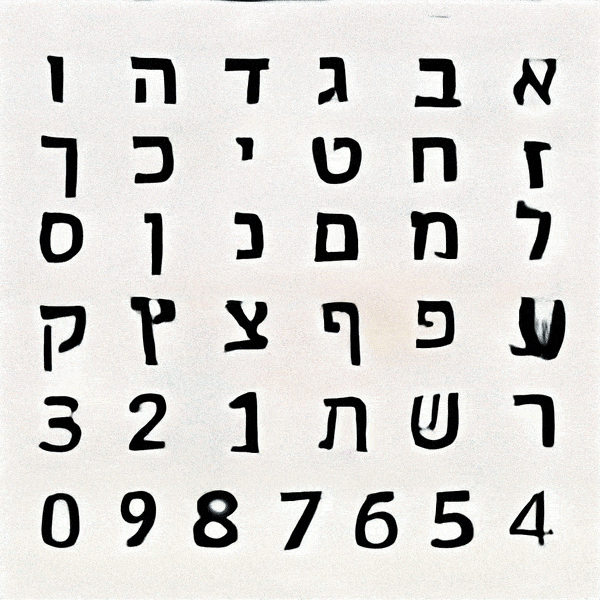
5000 Training steps / ~5 hrs cpu
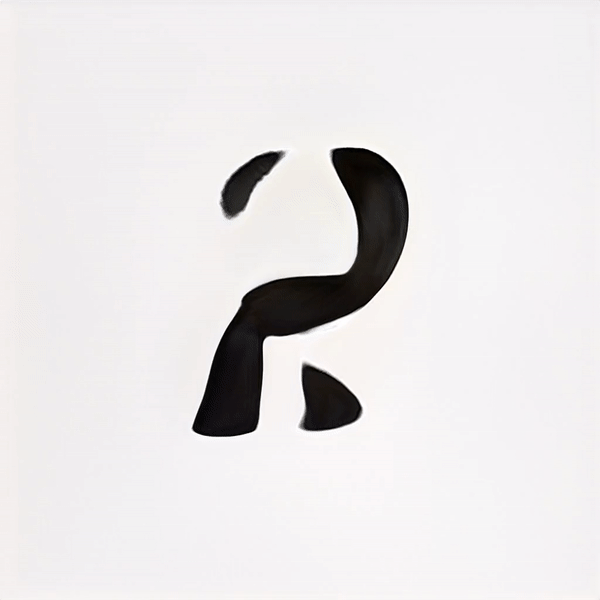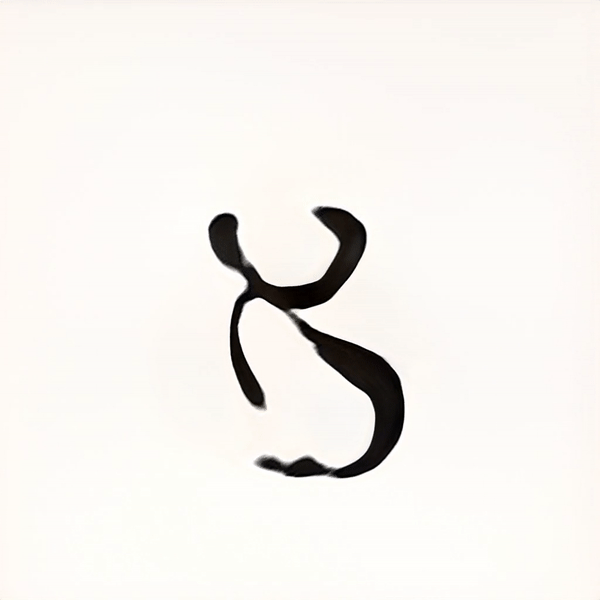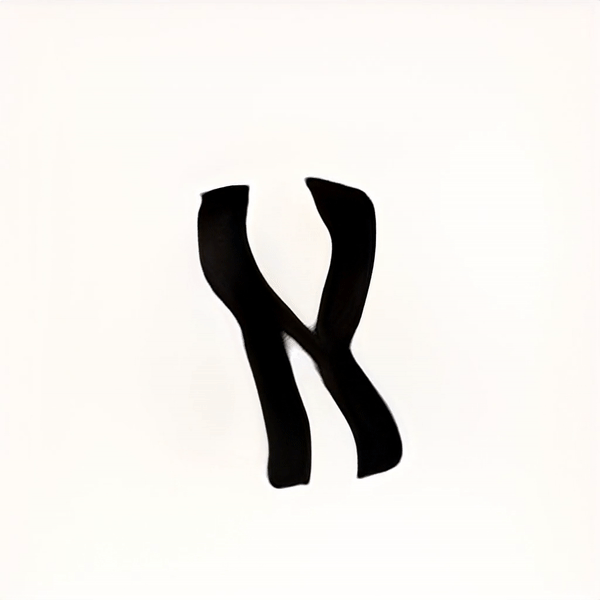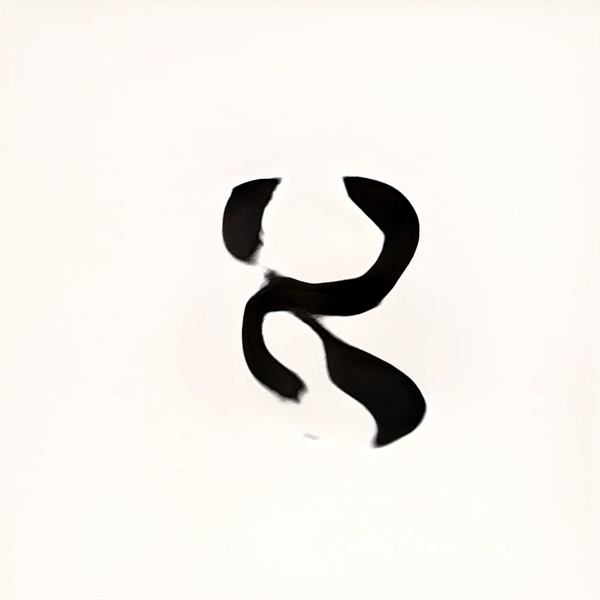
2000 Training steps / ~2 hrs cpu
Next step was to take these generated frames, randomise their order and upload them to Google’s Teachable Machine, there using an image classification model that was trained on the original labelled dataset of 150 images of each of the 150 glyphs, to select the first letterform for each glyph that reaches a threshold of a high accuracy rate.
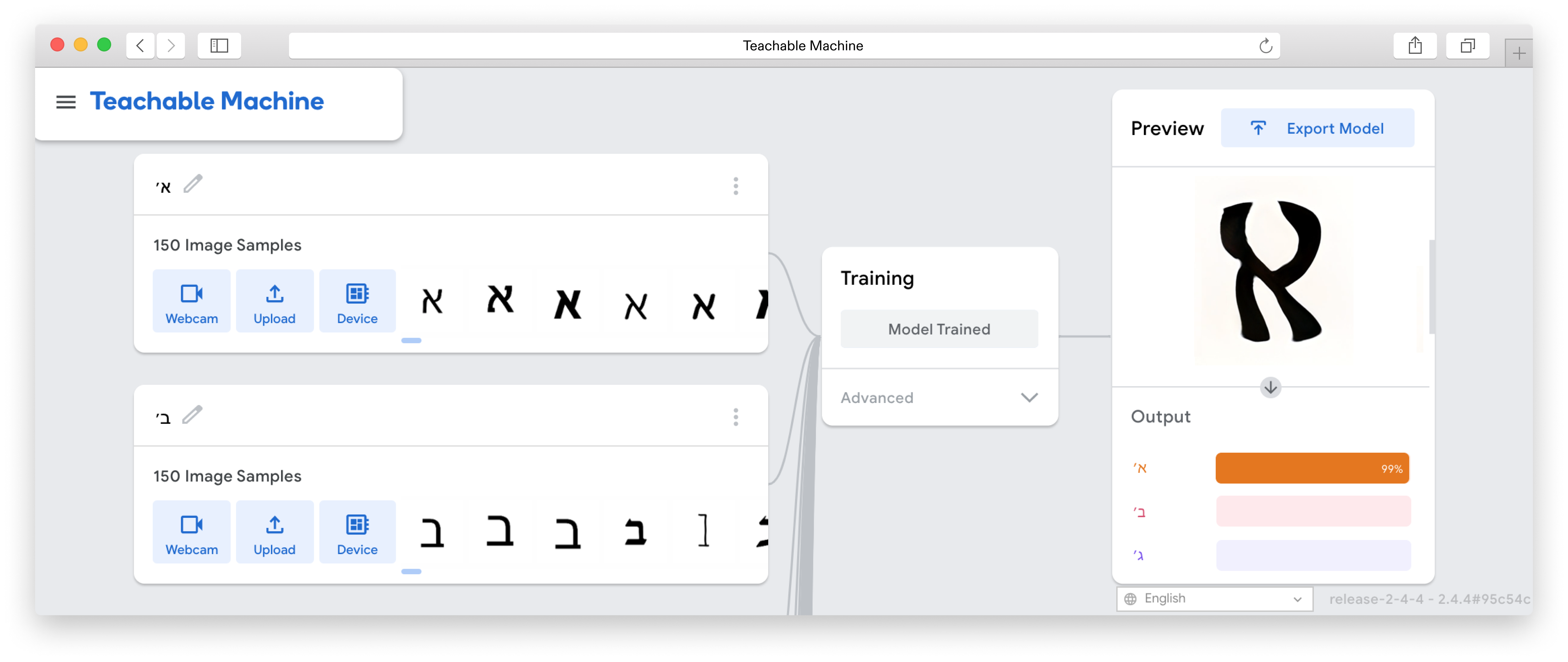
— The Result
After many trials and experimentation, it was apparent that as the training continued, the results began resembling designed letterforms to the point where it was hard to distinguish the generated letterforms from the trained data. Some characters took more training steps to create recognisable forms, but generally speaking each glyph was processed to a stage where the image classification model could recognise it after 2000 Training steps. Some letters such as ע (ein), ש (shin) and צ (tsadik) took substantially longer time to train. Other less complex glyphs were generated pretty quickly. Letting the machine have the ability to select which typeform would represent each glyph generated inconsistency in the form of the typeface, ranging from simple non serif letters to serif ones, and everything in between. This alphabet came out very crude, a ransom-letter-resembling assemblage of letterforms that may not be considered a typeface, had it been created solely by a designer.
Theoretically, this process could be used to quickly generate an infinite number of new fonts, but as long as the letterforms are trained separately, this general look to the typeface would remain the same.
Hebrew alphabet
א ב ג ד ה ו ז ח ט י כ ך ל מ ם נ ן ס ע פ ף צ ץ ק ר ש ת
Latin upper and lowercase alphabet
Aa Bb Cc Dd Ee Ff Gg Hh Ii Jj Kk Ll Mm Nn Oo Pp Qq Rr Ss Tt Uu Vv Ww Xx Yy Zz
Numrals, punctuation, currency & math signs
1 2 3 4 5 6 7 8 9 0
{[(;«#'?!’*»:)/]}
¢ ¥ £ $ ₪ €
‰ % ⁄ ‹ › ~ ≠ = ÷ × ± - +
The font supports Hebrew and various European languages.
Àà Áá Ââ Ãã Ää Åå Āā Ăă Ąą Ææ Çç Ćć Ċċ Čč Ďď Đđ Ðð Èè Éé Êê Ëë Ēē Ėė Ęę Ěě Ğğ Ġġ Ģģ Ħħ Ìì Íí Îî Ïï Īī Įį IJ ij Ķķ Ĺĺ Ļļ Ľľ Ŀŀ Łł Ññ Ńń Ņņ Ňň Ŋŋ Òò Óó Ôô Õõ Öö Øø Ōō Őő Œœ Ŕŕ Ŗŗ Řř Śś Şş Šš Șș ß Ţţ Ťť Ŧŧ Țț Ùù Úú Ûû Üü Ūū Ůů Űű Ųų Ŵŵ Ẁẁ Ẃẃ Ẅẅ Ýý Ŷŷ Ÿÿ Źź Żż Žž Þþ
לַגּוֹפָן יֵשׁ נִקּוּד מְתֻכְנָת וְהוּא תּוֹמֵךְ בְּעִבְרִית וּבְשָׂפוֹת נוֹסָפוֹת מִכָּל רַחֲבֵי אֵירוֹפָּה
“Type something here…”
"אפשר פה לכתוב משהו"
The font software is provided “as is”, without warranty of any kind, express or implied, including but not limited to any warranties of merchantability, fitness for a particular purpose and non infringement of copyright, patent, trademark, or other right. In no event shall the copyright holder be liable for any claim, damages or other liability, including any general, special, indirect, incidental, or consequential damages, whether in an action of contract, tort or otherwise, arising from, out of the use or inability to use the font software or from other dealings in the font software.